MPI FFTW, 3D Transforms
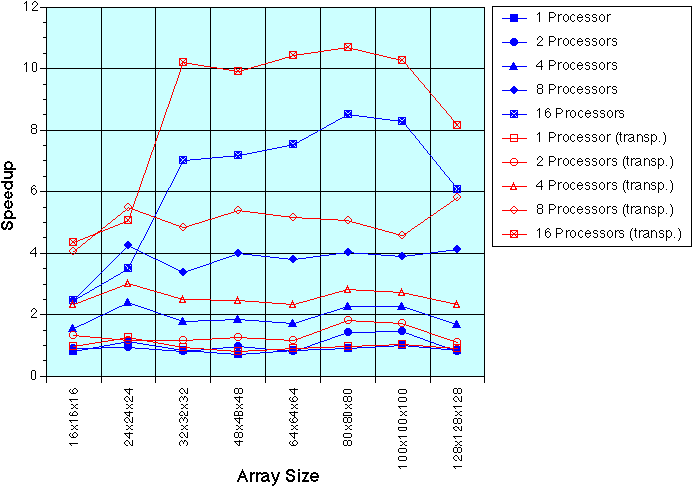
Cray 3D FFT (PCCFFT3D) (out-of-place)
Plotted value is speedup relative to uniprocessor FFTW.
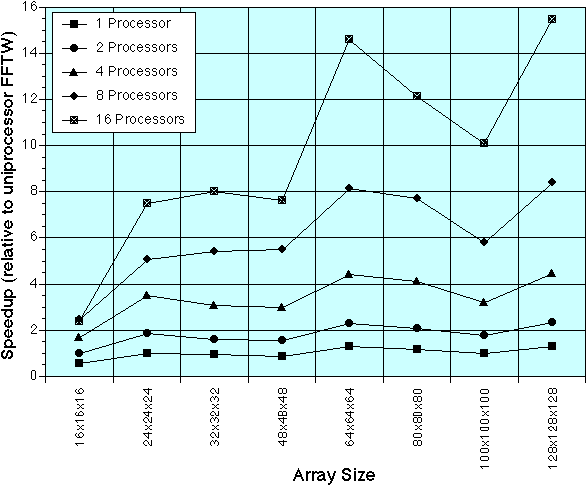
Two versions of the MPI FFTW are plotted. The first one returns the output data in the same format as the input data. The second version returns the output data in transposed order (this is faster because it saves the cost of an extra transpose).
We also had access to a Cray-provided, optimized FFT for the T3D. The speed of this software is shown at the bottom of the page for comparison. It should be noted that this transform is out-of-place, unlike the MPI FFTW transform. The performance of FFTW relative to the Cray FFT is disappointing, but we are working on a faster version.