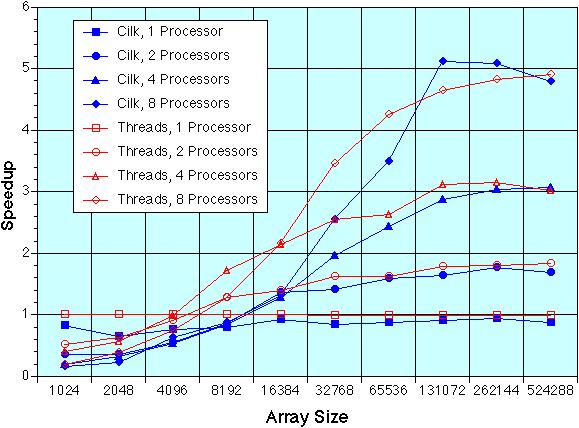
Cilk and Threads FFTW, 1D Transforms
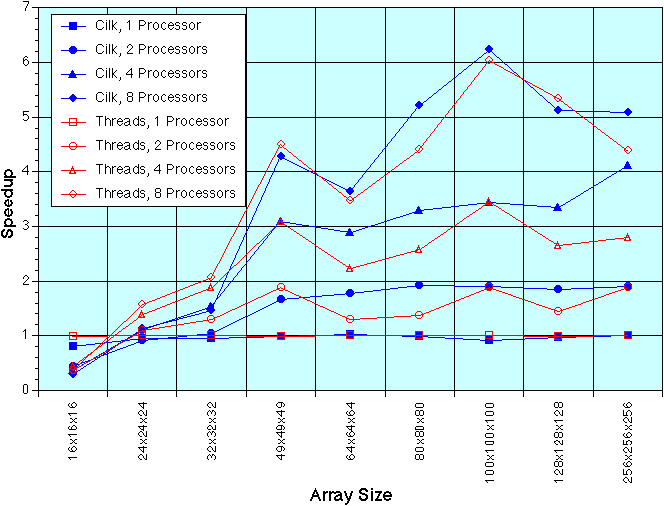
Cilk and Threads FFTW, 3D Transforms
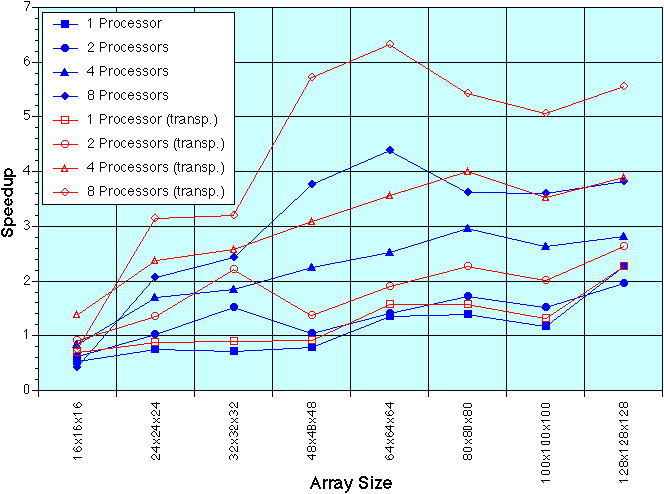
Next, we made the same measurements for the MPI version of FFTW and three-dimensional transforms. This is a shared-memory implementation of MPI.
We ran two versions of the this transform. The first one returns its output in the same format as its input. The second version returns it output in a transposed format (this is faster because it saves the cost of an extra transpose).